Automating AWS Lambda deployments using Bitbucket Pipelines and Bitbucket Pipes
Today we’ll talk about Bitbucket Pipes. It is a new feature in Bitbucket which can automate Lambda deployments on AWS.
So before we get our hands dirty, let’s get a basic overview.
What is AWS Lambda?
Lambda is the AWS managed service running functions-as-a-service. Lambdas work like other managed servies on AWS. We define a Python/Node/Java function and an API endpoint, and upload it to the Lambda service. Our function then handles the request-response cycle. AWS manages the underlying infrastructure resources for our function. This frees to focus on building our applications and not managing our infrastructure.
What is Bitbucket Pipelines?
Bitbucket Pipelines is the continuous-integration/continuous-delivery pipeline integrated into Bitbucket. It works by running a sequence of steps after we merge or review code. Bitbucket executed these steps in an isolated Docker container of our choice. You can review my past tutorial on Pipelines deployments here.
What is Bitbucket Pipes?
Bitbucket Pipes is the new feature we’ll test-drive today. It is a marketplace of third-party integrations. A Pipe is a parameterized Docker which contains ready-to-use code. It will look something like this:
- pipe: <vendor>/<some-pipe>
variables:
variable_1: value_1
variable_2: value_2
variable_3: value_3
Pipes by AWS, Google Cloud, SonarCube, Slack, and others are available already. They’re way to abstract away repeated steps. This makes code reviews easier and deployments more reliable. And it lets us focus on what is being done rather than how it is being done. If a third-party pipe doesn’t work for you, you can even write you own!
These are some of the providers that provide Pipes today:

Goal: Deploy a Lambda using Pipes
So our goal today is as follows: We want to deploy a test Lambda function using the new Pipes feature.
To do this, we’ll need to:
- Create a test function.
- Configure AWS credentials for Lambda deployments.
- Configure credentials in Bitbucket.
- Write our pipelines file which will use our credentials and a Pipe to deploy to AWS.
Step 1: Create a test function
Let’s start with a basic test function. Create a new repo, and add a new file called lambda_function.py with the following contents:
def lambda_handler(a, b):
return "It works :)"
Step 2: Configure AWS credentials
We’ll need an IAM user with the AWSLambdaFullAccess managed policy.
Add this user’s access and secret keys to the Repository variables of the repo. Make sure to mask and encrypt these values.
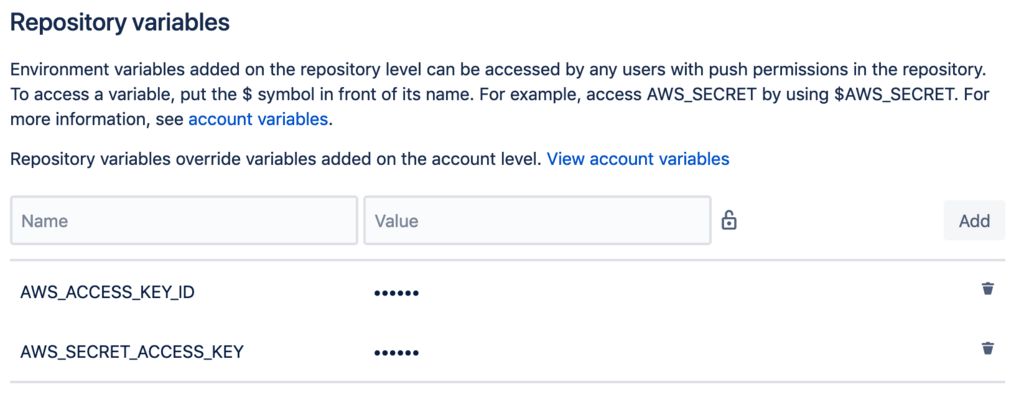
Add the keys either at the Account level, the Deployment level, or the Repository level. You can find more information about these here.
Step 3: Create our Pipelines file
Now create a bitbucket-pipelines.yml file and add the following:
pipelines:
default:
- step:
name: Build and package
script:
- apt-get update && apt-get install -y zip
- zip code.zip lambda_function.py
artifacts:
- code.zip
- step:
name: Update Lambda code
script:
- pipe: atlassian/aws-lambda-deploy:0.2.1
variables:
AWS_ACCESS_KEY_ID: ${AWS_ACCESS_KEY_ID}
AWS_SECRET_ACCESS_KEY: ${AWS_SECRET_ACCESS_KEY}
AWS_DEFAULT_REGION: 'us-east-1'
FUNCTION_NAME: 'my-lambda-function'
COMMAND: 'update'
ZIP_FILE: 'code.zip'
The first step: in the pipeline will package our Python function in a zip file and pass it as an artifact to the next step.
The second step: is where the magic happens. atlassian/aws-lambda-deploy:0.2.1 is a Dockerized Pipe for deploying Lambdas. Its source code can be found here. We call this Pipe with six paramters: our AWS credentials, the region where we want to deploy, the name of our Lambda function, the command we want to execute, and the name of our packaged artifact.
Step 4: Executing our deployment
Committing the above changes in our repo will trigger a pipeline for this deployment. If all goes well, we should see the following:
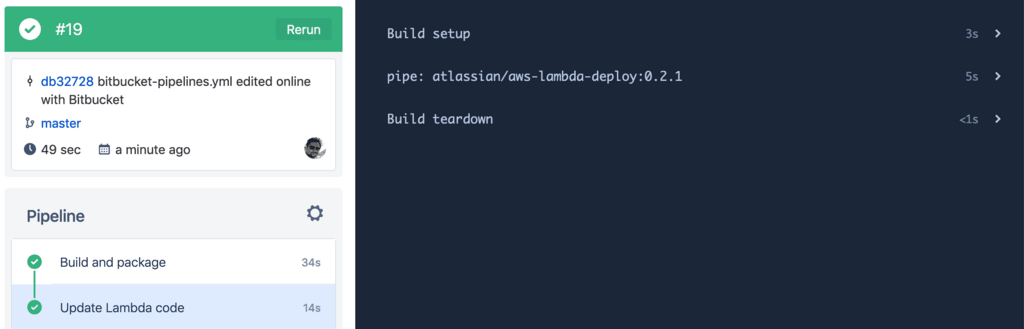
Wrapping it up
With the above pipeline ready, we can use other Bitbucket features to make improve it. Features like merge checks, branch permissions, and deployment targets can make deployments smoother. We can also tighten the IAM permissions to ensure it has access to only the resources it needs.
Using Pipes in this way has the following advantages:
- They simplify pipeline creation and abstract away repeating details. Just paste in a vendor-supplied pipeline, pass in your parameters, and that’s it!
- Code reviews become easier. Ready-to-use Pipes can abstract away complex workflows.
- Pipes use semantic versioning, so we can lock the Pipe version to major or minor versions as we choose. Changing a Pipe version can go through a PR process, making updates safer.
- Pipes can even send Slack and PagerDuty alerts after deployments.
And that’s all. I hope you’ve enjoyed this demo. You can find more resources below.
Thanks, and happy coding :)
Resources

Help me fuel up so I can keep typing typing typing...
&emoji=☕&slug=ayushsharma&button_colour=FFDD00&font_colour=000000&font_family=Cookie&outline_colour=000000&coffee_colour=ffffff)
